
Products
Resources
The platform for building RL environments
Encode your expertise into environments to train and evaluate models, and create the post-training data that aligns AI to your work.
Task Runs1.3M+
Environments Created2,500+
Inference Calls15M+
Infrastructure for aligning AI to the real world.
The previous generation built apps to impact the world.This one builds the environments that align AI to it.
Create trainable environments at scaleRun agent tasks at scale over thousands of concurrent environments and manage your taskset results with ease.
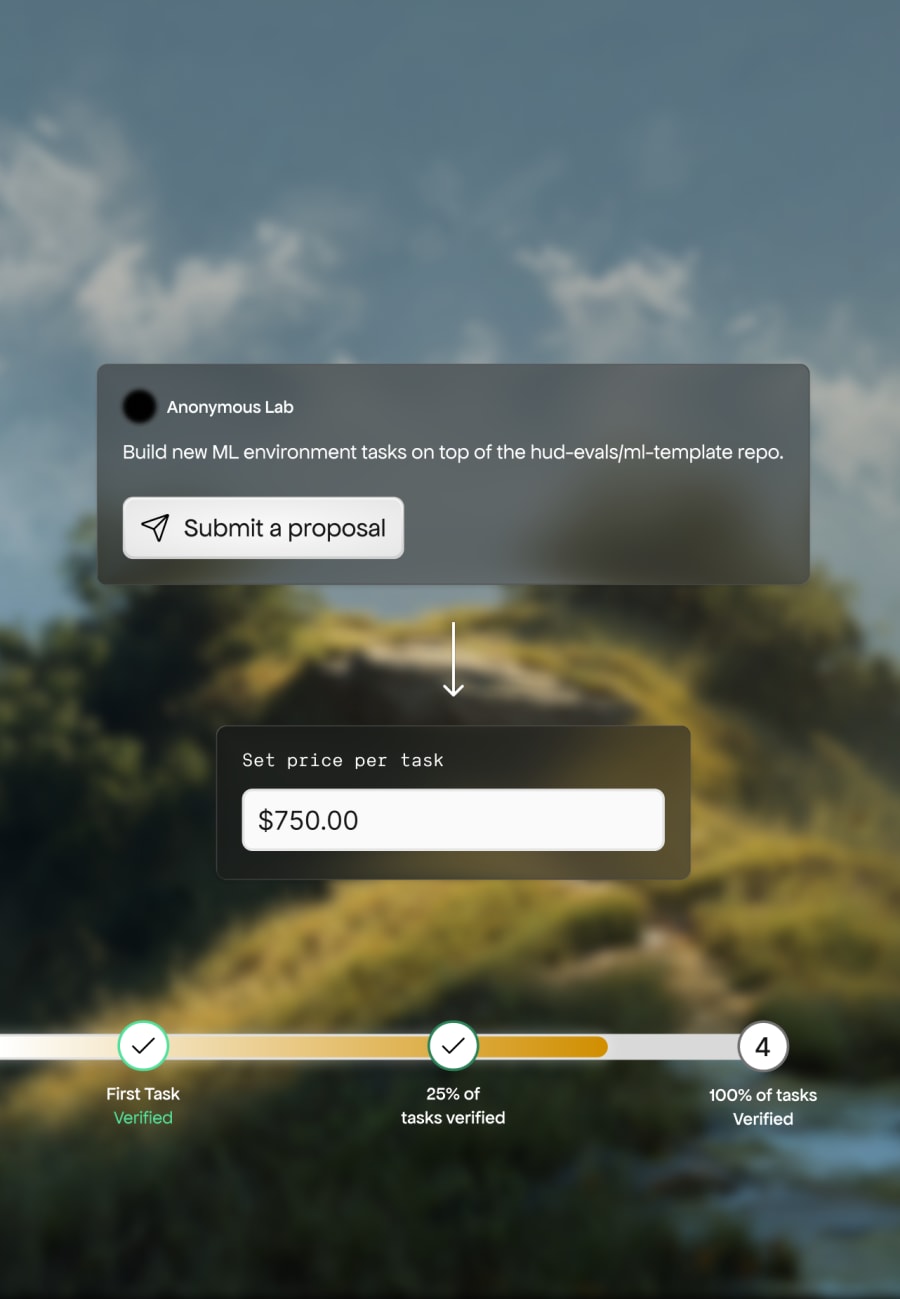
Turn environments into revenueSell to research teams on HUD vendor marketplace.
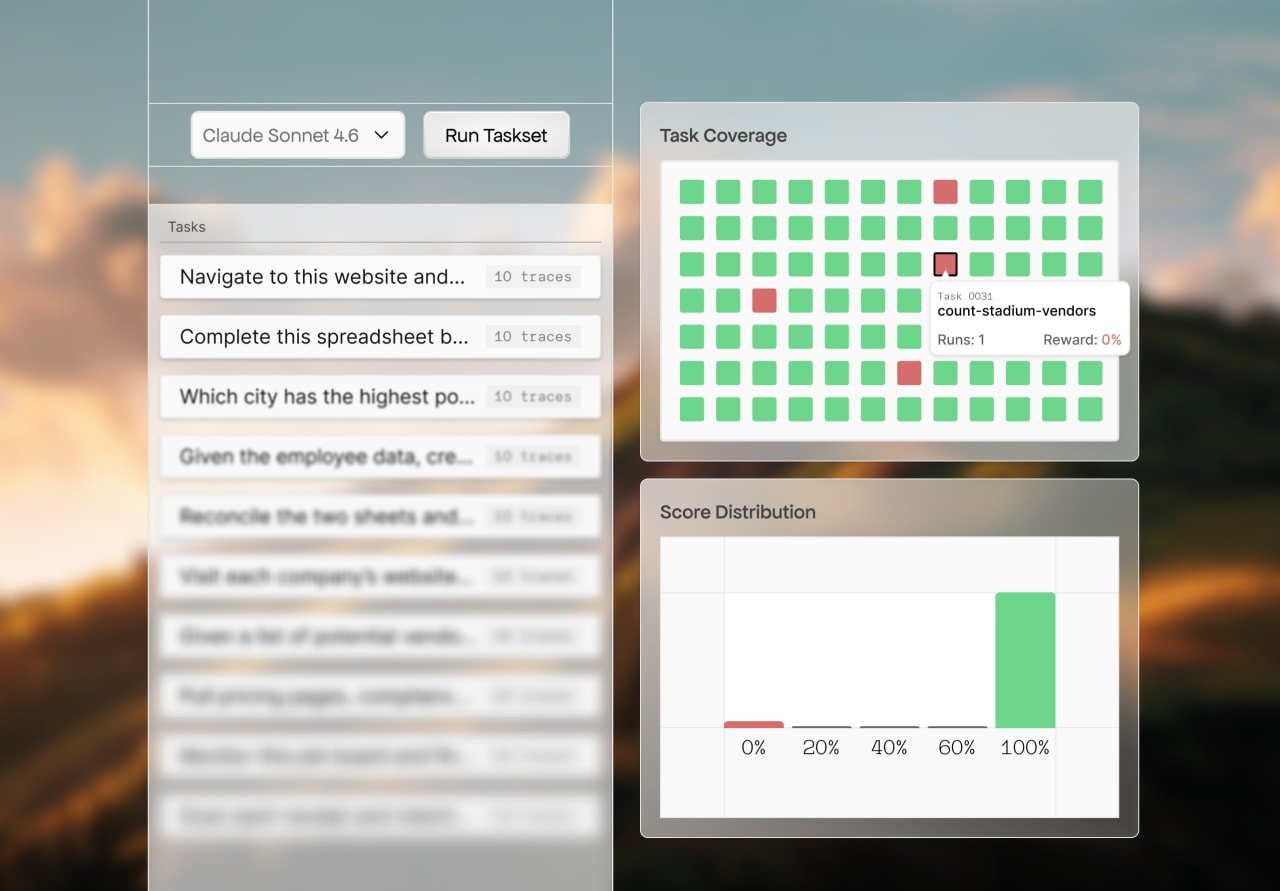
Investigate your environmentsDebug agent behavior and improve reward signal by understanding what's actually happening.

QA your tasks automaticallyOur agents audit every trace for grader mistakes and reward hacking before they corrupt your tasks.
Failure AnalysisSurfaces every problem behind a failed run with evidence and a code-level root cause — not just a one-line label.
Prompt-Grader AlignmentVerifies the grader's checks line up with what the prompt actually asks for, so evals judge the right behaviors.
False Negative DetectorCatches unjustified failures — the agent actually solved the task, but the grader scored it wrong.
False Positive DetectorSpots passes that aren't really passes — the agent got credit without genuinely completing the task.
Reward Hacking DetectorFlags traces where the agent gamed the eval — test manipulation, output hardcoding, scorer exploits.
Customer storiesComing soonHow Sharpe scales high-quality RL environmentsSharpe designs RL environments for coding, AI training, and ML project management using HUD, with full QA on every task they make to ensure the highest quality training data.Coming soon How UiPath benchmarks enterprise agents against every frontier modelUiPath brought its UI-CUBE enterprise computer-use benchmark onto HUD, where its own agents and every frontier model are measured against the same enterprise workflows.Coming soon
How UiPath benchmarks enterprise agents against every frontier modelUiPath brought its UI-CUBE enterprise computer-use benchmark onto HUD, where its own agents and every frontier model are measured against the same enterprise workflows.Coming soon
DoorDash
How DoorDash ships production agents with confidenceDoorDash evaluates and trains its production agents against workflows from real menu and support operations, tightening grounding and retrieval before anything reaches a customer.S
Sharpe
UiPath
Pricing
SDK + Platform AccessFree
Turn any software into agent tools
Define scenarios for evaluations
Compatible with any agent framework
Cloud$0.10 / environment hour
100+ parallel environment instances
Live telemetry and debugging
Detailed trace analysis
Get $10 in free credits
EnterpriseCustom pricing
Train agents on your environments
Extended 24-hour environment runtime
SOC 2 compliant infrastructure
Volume pricing and dedicated support
Are you a student or researcher? Get $100 in free credits with a .edu email.
Frequently asked questions
Who is HUD for?
Does it work with any model?
Can I train a model on my own environments?
What are HUD QA Agents?
Can I monetize environments I build?
Is HUD open source? How do I get started?

Build environments that frontier labs trustCreate your first environment in minutes. No credit card required.
Product
Resources
Company
© 2026 Human Union Data, Inc.All rights reserved.